Ship an AI Agent Registry + IAM in 7 Days (MCP, AgentKit, Agent 365, OpenTelemetry)
If your org spun up multiple AI agents this year, you likely have a sprawl problem: unknown agents, inconsistent permissions, and thin audit trails. Here’s a pragmatic 7‑day plan to stand up an agent registry + identity & access management (IAM) layer your security team can live with—while keeping builders fast.
Why now? Enterprise‑grade agent platforms and standards matured quickly: OpenAI announced AgentKit with a connector registry and eval tooling; Microsoft introduced Agent 365 for governing bot fleets; and industry protocols like MCP (for tools) and A2A (for agent‑to‑agent) are becoming the default interop layer. Add OpenTelemetry’s emerging GenAI agent semantics and you have the backbone for policy and audit. OpenAI AgentKit citeturn2search2 Microsoft Agent 365 citeturn0news14 Anthropic MCP citeturn2search0 A2A protocol citeturn3search5 OpenTelemetry GenAI agent spans. citeturn3search2
Who this is for
- Startup CTOs/PMs who need guardrails without slowing shipping.
- E‑commerce ops teams adding checkout recovery, returns, or support agents.
- Platform/SRE/SecOps leaders who must prove least‑privilege access and produce audit logs.
The 7‑Day Registry + IAM Plan
Day 1 — Inventory and scope
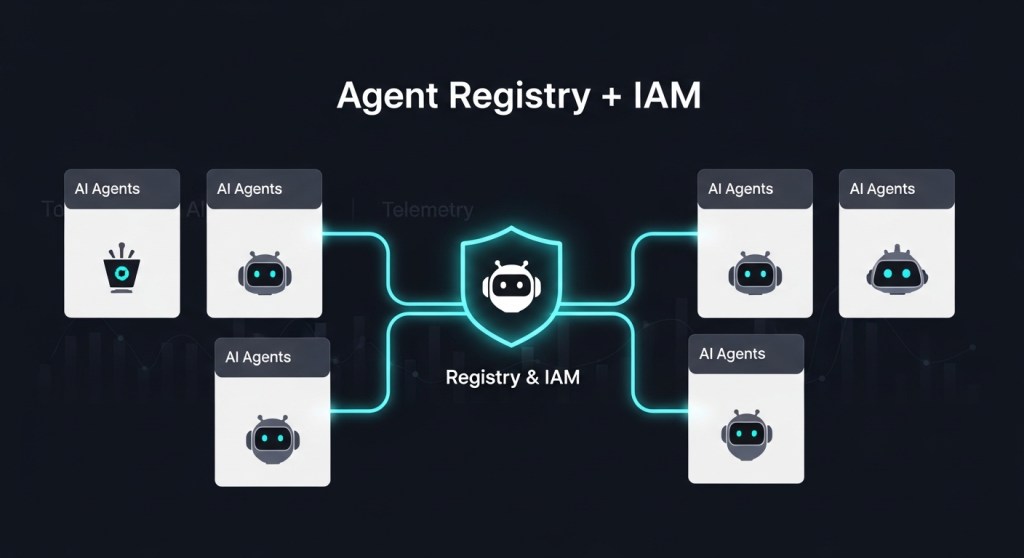
List every agent in use (or planned): owner, purpose, models, tools/APIs, data touched, and environments. Define scopes per agent (read‑only vs write, sandbox vs prod). Decide your registry home: vendor (e.g., Agent 365) or vendor‑agnostic (Git repo + YAML/JSON + service catalog). Microsoft’s Agent 365 positions itself as an admin console with registry, security, and telemetry integrated with Entra—worth evaluating if you’re a Microsoft shop. The Verge coverage. citeturn3news12
Day 2 — Establish the Agent Registry
Pick a registry format and publish agent cards describing metadata, capabilities, scopes, owners, and on‑call. For interop, ensure your agent descriptors can map to A2A concepts so agents can discover and collaborate across vendors later. If you adopt OpenAI AgentKit, use its Connector Registry for standardized tool access and change control. If you’re Anthropic‑first, register tools via MCP servers and keep agent descriptors alongside them. AgentKit citeturn2search2 MCP docs citeturn2search4 A2A docs. citeturn3search5
Day 3 — Identity, secrets, and least privilege
Create first‑class identities for agents (service principals/app registrations) and bind only the minimal scopes needed (e.g., orders:read, returns:create). Centralize secrets; rotate automatically. For browser‑automation agents, prevent credential exposure with human‑in‑the‑loop autofill tools now emerging in the ecosystem (e.g., 1Password’s “Secure Agentic Autofill”). See The Verge. citeturn3news13
Day 4 — Policy and guardrails
Codify policies as code: allowed tools, data boundaries, write paths, approvals, handoff rules, and spending limits. If you’re piloting Agent 365, map policies to Entra roles and DLP; in OpenAI AgentKit, use the admin control panel + connector scopes. Keep a policy README in the registry and require changes via PRs. AgentKit policy/admin notes citeturn2search2 Agent 365 posture. citeturn0news14
Day 5 — Telemetry and audit with OpenTelemetry
Instrument agents and tools with OpenTelemetry GenAI agent spans. Capture: agent.create, agent.invoke, tool.invoke, result status, cost, and PII‑safe attributes. Pipe to your observability stack (e.g., OTLP → collector → your backend). This unlocks SLOs, anomaly detection, and forensic trails. GenAI agent span conventions. citeturn3search2
Day 6 — Automated evals + red teaming
Before go‑live, run agent evals against risky flows: prompt injections, tool abuse, data exfil, and hallucinations. OpenAI’s Evals for Agents adds datasets, trace grading, and automated prompt optimization—use it even if you route to non‑OpenAI models. Pair evals with manual red‑teaming and budget guardrails. Evals for Agents. citeturn2search2
Day 7 — SLOs, on‑call, and change management
Publish agent SLOs (task success rate, TTFT, TPOT, handoff rate, cost/task). Set alert thresholds; document runbooks; rehearse handoffs. Lock promotion paths (dev → staging → prod) and require eval/telemetry gates at each step.
Reference architecture (vendor‑agnostic)
- Registry: agent cards (YAML/JSON), owners, scopes, policy refs.
- Identity: per‑agent service identity, scoped secrets, rotation.
- Interop: tools via MCP servers; cross‑vendor collaboration via A2A. MCP citeturn2search0 A2A. citeturn3search5
- Policy: least privilege, write‑paths, approvals, spend caps.
- Observability: OpenTelemetry genAI spans → dashboards, alerts, audits. Spec. citeturn3search2
- Evals: scenario suites + trace grading; pre‑prod gate. OpenAI Evals. citeturn2search2
Make vs. buy (fast guidance)
- Microsoft‑centric org? Pilot Agent 365 for registry + Entra policy. Layer OpenTelemetry for vendor‑neutral telemetry. Wired; The Verge. citeturn0news14turn3news12
- OpenAI‑centric org? Use AgentKit for connector governance + evals; register MCP servers for portability. AgentKit. citeturn2search2
- Best‑of‑breed / multi‑model? Keep a Git‑backed registry, use MCP for tools and A2A for agent collaboration; add OpenTelemetry everywhere for consistent auditing. MCP; A2A. citeturn2search0turn3search5
Operational tips from early adopters
- Start write‑blocked: ship read‑only agents first; flip to write with approvals after evals pass.
- Tag every span: owner, agent version, policy version, and environment. It saves incidents later. OpenTelemetry guide. citeturn3search2
- Separate human and agent credentials: where browser agents are unavoidable, use an approval‑gated autofill pattern to keep secrets away from LLM memory. Example. citeturn3news13
- Future‑proof interop: A2A is gaining traction and Microsoft publicly aligned with Google’s standard for linking agents—design registries with cross‑vendor discovery in mind. TechCrunch. citeturn0search1
How this fits with your next builds
Once your registry + IAM is live, you can ship new agents faster and safer. Try these next:
- Build an Internal AI Agent Control Plane in 7 Days (MCP + A2A + OpenTelemetry)
- Ship Agent SLOs That Matter
- The 30‑Day AI Agent Security Hardening Plan
- AI Agent FinOps: Cut Costs 25–40%
SEO snapshot
Primary keyword: AI agent identity and access management. Secondary: agent registry, Agent 365, AgentKit, MCP, OpenTelemetry genAI. Current SERP includes vendor explainers and governance guides; few step‑by‑step build plans—this post fills that gap. Sources: AgentKit, Agent 365, OpenTelemetry, A2A. citeturn2search2turn0news14turn3search2turn3search5
Call to action: Need help standing this up in a week? Book a free 30‑minute “Agent Registry & IAM” workshop with HireNinja. We’ll review your agents, map scopes, and leave you with a policy + telemetry blueprint.