
AI Shopping Agents for Holiday 2025: What Works Now (and What to Park for 2026)
Updated: November 16, 2025
Consumer buzz is high, but fully autonomous, end‑to‑end shopping agents are not broadly reliable yet. That doesn’t mean you should wait. This guide shows what founders and e‑commerce teams can deploy this quarter to lift revenue and reduce support load—without betting the checkout on immature tech.
Reality check: where agents stand today
Major players have accelerated agent capabilities in 2025—OpenAI’s AgentKit to build and ship agents, Google’s Project Mariner for web‑using agents, Anthropic’s browser agent for Chrome, and Amazon’s Nova Act. These signal a durable platform shift, but most consumer shopping agents still need human confirmation for high‑stakes steps like payments and address validation. See recent coverage and announcements: OpenAI AgentKit, Google Project Mariner, Anthropic’s Chrome agent, and Amazon Nova Act. For a recent e‑commerce reality check, see WIRED’s holiday‑shopping report (not yet ready for full autonomy).
What actually works now for e‑commerce (and moves the needle)
- Checkout recovery agent that personalizes nudges and incentives across email/SMS/chat, then escorts the shopper back to a pre‑filled checkout. See our 7‑day playbook and ROI model: Checkout Recovery Agent.
- PDP and FAQ copilot that answers product, sizing, shipping, and policy questions inline, with verbatim citations to your catalog, policies, and reviews. Make your site “agent‑readable” in a weekend: NLWeb + Schema.org + MCP.
- Returns/exchanges agent that enforces policy, issues labels, and proposes exchanges or store credit to save revenue while cutting tickets.
- Post‑purchase support agent (order status, address fix window, WISMO, warranties) integrated with your helpdesk and 3PL.
- Subscription save agent that offers cadence tweaks, partial skips, or low‑friction downsells before a churn event.
Each of these is bounded, measurable, and compatible with human‑in‑the‑loop confirmation for risky actions.
What to park for 2026
- Truly autonomous end‑to‑end shopping (agent chooses product, compares retailers, pays, and handles delivery exceptions) across arbitrary sites.
- Open web browser agents with full purchasing power without a robust identity, permissioning, and transaction‑limit framework.
- Unbounded multi‑agent swarms operating customer‑visible flows without clear SLOs, budgets, and rollback paths.
A pragmatic 14‑day rollout plan
- Days 1–2: Pick one high‑ROI use case (checkout recovery or PDP copilot) and define guardrails: must‑link policies, max discount ladders, refund limits.
- Days 2–4: Make your store agent‑ready with structured content. Publish or update product schema, policies, and FAQs; expose endpoints with MCP/NLWeb so agents have ground truth. Start here: Agent‑Ready in a Weekend.
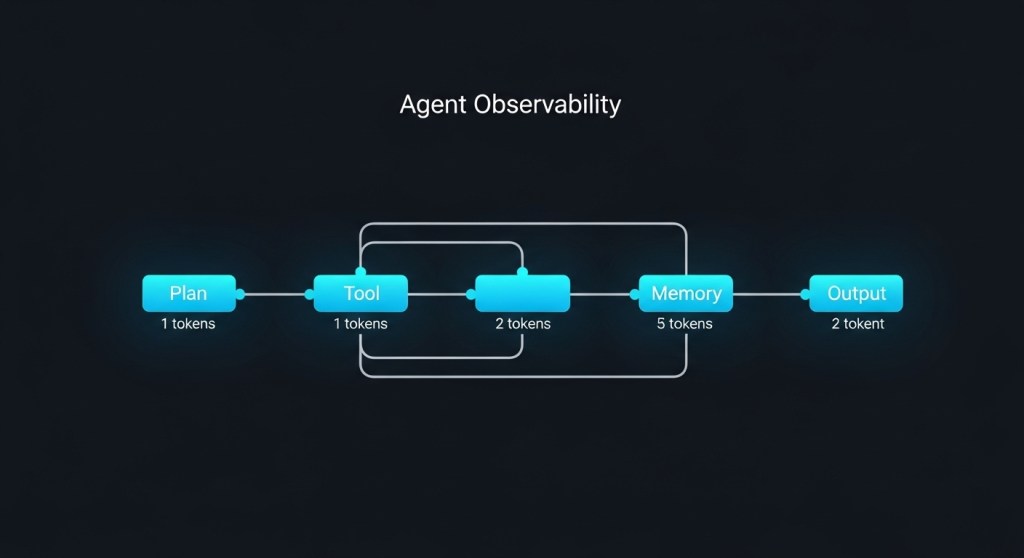
- Days 3–6: Instrumentation. Add OpenTelemetry spans around agent steps; log tool calls and cost per session. Use our blueprint: Agent Observability Blueprint.
- Days 5–8: Identity & permissions. Implement customer session binding, rate limits, and transaction caps; require explicit user confirmation for payment. See: Stop Agent Impersonation.
- Days 7–10: Red‑team before GA. Test prompt injection, tool abuse, policy bypass, and social engineering using our checklist: Agent Red Teaming 2025.
- Days 9–12: Soft‑launch to 10–20% of traffic; run A/B against a strong baseline; protect budget with per‑session spend caps.
- Days 12–14: Review and scale. If KPIs clear targets (below), expand exposure and add one more bounded use case.
Target KPIs and go/no‑go gates
- Checkout recovery agent: +8–15% uplift in recovered revenue; CAC‑adjusted ROAS positive within 14 days; <$0.35 AI cost per recovered cart.
- PDP/FAQ copilot: +10–20% lift in PDP‑to‑add‑to‑cart for engaged sessions; < 3% hallucination rate (measured by citation mismatch audits); CSAT ≥ 4.4/5.
- Support agent: 35–60% ticket deflection on WISMO and returns; FCR ≥ 70% with human fallback < 5 seconds median.
- Universal gates: zero unauthorized refunds/credits; ≤ 0.1% false promise rate; max cost/session $0.20 (informational), $0.80 (transactional).
Reference architecture (works on Shopify or Woo)
Channel surface: PDP widget, chat bubble, email/SMS, and help center.
Reasoning runtime: your LLM/agent platform of choice; consider vendor SDKs maturing fast (e.g., AgentKit).
Tools: product/pricing search, inventory, discount engine, order APIs, shipping rates, RMA, payments (read‑only unless user confirms).
Interoperability: align with emerging agent‑to‑agent protocols so you’re not boxed in. Microsoft signaled support for Google’s A2A this year—useful for future multi‑agent workflows. Details.
Observability & spend: OTel traces, per‑tool metrics, and a budget guard that aborts/backs off when costs spike. See our cost control playbook.
UX patterns that boost trust and conversion
- Explainability on demand: a “Why this?” link that shows sources (catalog, policy page, prior order) with timestamps.
- Consent gates: explicit “Approve purchase” with last‑mile details summarized (SKU, price, address, delivery ETA). No silent charges.
- Receipts + audit trail: log agent action IDs on the order timeline so humans can review issues quickly.
- Fallbacks: when confidence or tool latency drops, hand off to a human and preserve the agent’s context for continuity.
Costs you should expect (and how to cap them)
For the above workloads, we routinely see blended AI costs in the $0.05–$0.40/session range, depending on model, context window, and tool call frequency. Enforce:
- Caching for repeated policy and shipping answers.
- Routing: cheap models for retrieval, premium models for conversion moments.
- Batching async tasks (e.g., email/SMS drafting) and deferring non‑critical calls.
Our cost controls guide shows how to trim 30–60% without hurting CX: Unit Economics 2025.
Security, compliance, and go‑live hygiene
- Map runtime controls to frameworks (ISO 42001, NIST AI RMF, EU AI Act), keep evidence. Use our Compliance Checklist 2025.
- Run an agent evaluation lab with golden paths and adversarial scenarios before GA: Evaluation Lab in 7 Days.
- Harden identity, permissions, and transaction controls for anything that touches money: Identity & Permissions.
Looking ahead
Expect 2026 to bring tighter integrations between platform‑native agents (OpenAI, Google, Anthropic, Amazon) and commerce backends, plus safer cross‑agent collaboration via shared protocols. Keep building the prerequisites now—structured content, tooling interfaces, observability, and governance—so you can adopt deeper autonomy when the risk/reward balance flips.




![Deploy an AI Checkout Recovery Agent for Shopify/WooCommerce in 7 Days [2025 Playbook + ROI Model]](https://blog.hireninja.com/wp-content/uploads/2025/11/image_52dfe9a2-ab34-435d-a499-7bf6b8f3a9e9.jpeg?w=1024)
![Make Your Website Agent‑Ready in a Weekend: NLWeb + Schema.org + MCP [2025 Guide]](https://blog.hireninja.com/wp-content/uploads/2025/11/image_ee2098b8-3e04-41cf-93c5-1472e8379094.jpeg?w=1024)

